- Published on
逻辑回归:从理论到实践
- Authors
- Name
欢迎来到这场逻辑回归的学习之旅!无论你是机器学习新手还是希望巩固知识,这篇博客将带你从零开始构建逻辑回归模型。我们将通过预测学生录取和芯片质量的实际问题,结合理论、Python代码和可视化,让学习变得既有趣又实用。让我们开始吧!
你将学到什么
- 逻辑回归在二分类问题中的工作原理。
- 实现核心函数,如 Sigmoid、成本函数和梯度下降。
- 数据可视化和决策边界。
- 使用正则化处理复杂数据集。
目录
1 - 准备工具包
在开始之前,我们需要准备一些 Python 工具包,它们将帮助我们处理数据、进行计算和可视化结果。以下是你需要的内容:
- NumPy:用于快速数组操作。
- Matplotlib:用于绘制数据和结果。
utils.py:一个辅助文件,包含load_data()和plot_data()等函数。
运行以下代码来设置:
import numpy as np
import matplotlib.pyplot as plt
from utils import *
import copy
import math
%matplotlib inline
准备好这些工具后,我们就可以开始探索逻辑回归了!
2 - 逻辑回归基础
让我们从一个经典问题开始,逐步构建逻辑回归模型。
2.1 问题背景
假设你是一名大学管理员,你希望根据申请者的两次考试成绩预测他们是否会被录取。你有历史数据:考试成绩和录取结果(1 表示录取,0 表示未录取)。我们的目标是创建一个模型,估计录取的概率。
2.2 数据探索
首先,加载数据集:
X_train, y_train = load_data("data/ex2data1.txt")
查看数据
让我们看看数据长什么样:
print("X_train的前五行:\n", X_train[:5])
print("y_train的前五个值:\n", y_train[:5])
输出:
X_train的前五行:
[[34.62365962 78.02469282]
[30.28671077 43.89499752]
[35.84740877 72.90219803]
[60.18259939 86.3085521]
[79.03273605 75.34437644]]
y_train的前五个值:
[0. 0. 0. 1. 1.]
X_train:一个 (100, 2) 数组,包含考试成绩。y_train:一个 (100,) 数组,包含录取标签。
可视化数据
散点图可以帮助我们理解数据:
plot_data(X_train, y_train, pos_label="录取", neg_label="未录取")
plt.ylabel('考试2成绩')
plt.xlabel('考试1成绩')
plt.legend(loc="upper right")
plt.show()
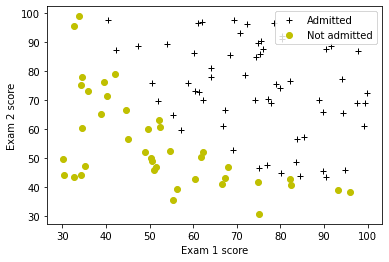
录取的学生(1)往往有更高的成绩,而未录取的学生(0)则集中在较低的区域。我们的模型将绘制一条线——或边界——来分隔这些群体。
2.3 Sigmoid 函数
逻辑回归使用 Sigmoid 函数将预测值映射到 0 到 1 之间:
其中,z = w * x + b,w 是权重向量,b 是偏置。让我们编写它:
def sigmoid(z):
return 1 / (1 + np.exp(-z))
测试一下:
print("sigmoid(0) =", sigmoid(0))
print("sigmoid([-1, 0, 1, 2]) =", sigmoid(np.array([-1, 0, 1, 2])))
输出:
sigmoid(0) = 0.5
sigmoid([-1, 0, 1, 2]) = [0.26894142 0.5 0.73105858 0.88079708]
Sigmoid 函数将任何实数映射到 (0, 1)——非常适合表示概率!
2.4 成本函数
为了训练模型,我们需要一个成本函数来衡量预测误差:
其中 f(x^(i)) = sigmoid(w * x^(i) + b)。实现它:
def compute_cost(X, y, w, b):
m = X.shape[0]
cost = 0.0
for i in range(m):
z = np.dot(X[i], w) + b
f_wb = sigmoid(z)
cost += -y[i] * np.log(f_wb) - (1 - y[i]) * np.log(1 - f_wb)
return cost / m
使用初始参数测试:
initial_w = np.zeros(2)
initial_b = 0.0
cost = compute_cost(X_train, y_train, initial_w, initial_b)
print(f"初始成本: {cost:.3f}")
输出:
初始成本: 0.693
这为我们提供了一个优化的起点。
2.5 梯度下降
梯度下降通过调整 w 和 b 来减小成本。梯度为:
编码实现:
def compute_gradient(X, y, w, b):
m, n = X.shape
dj_dw = np.zeros(n)
dj_db = 0.0
for i in range(m):
z = np.dot(X[i], w) + b
f_wb = sigmoid(z)
err = f_wb - y[i]
dj_db += err
dj_dw += err * X[i]
dj_dw /= m
dj_db /= m
return dj_dw, dj_db
测试:
dj_dw, dj_db = compute_gradient(X_train, y_train, initial_w, initial_b)
print(f"初始梯度: w = {dj_dw}, b = {dj_db}")
输出:
初始梯度: w = [-12.00921659 -11.26284221], b = -0.1
这些梯度将指导我们的优化过程。
2.6 训练模型
以下是梯度下降算法:
编码实现:
def gradient_descent(X, y, w_in, b_in, cost_function, gradient_function, alpha, num_iters):
J_history = []
w = w_in
b = b_in
for i in range(num_iters):
dj_dw, dj_db = gradient_function(X, y, w, b)
w -= alpha * dj_dw
b -= alpha * dj_db
cost = cost_function(X, y, w, b)
J_history.append(cost)
if i % 1000 == 0:
print(f"迭代 {i:4}: 成本 {cost:8.2f}")
return w, b, J_history
运行它:
np.random.seed(1)
initial_w = 0.01 * (np.random.rand(2) - 0.5)
initial_b = -8.0
w, b, J_history = gradient_descent(X_train, y_train, initial_w, initial_b,
compute_cost, compute_gradient, 0.001, 10000)
print(f"训练后的 w, b: {w}, {b}")
输出:
迭代 0: 成本 0.96
迭代 1000: 成本 0.31
...
训练后的 w, b: [ 0.07125356 -0.06482832], -8.188577238533804
成本逐渐减小,表明模型正在学习!
2.7 决策边界可视化
可视化决策边界:
plot_decision_boundary(w, b, X_train, y_train)
plt.ylabel('考试2成绩')
plt.xlabel('考试1成绩')
plt.legend(loc="upper right")
plt.show()
这条线很好地分隔了录取和未录取的学生。
2.8 评估模型
定义预测函数:
def predict(X, w, b):
m = X.shape[0]
p = np.zeros(m)
for i in range(m):
z = np.dot(X[i], w) + b
f_wb = sigmoid(z)
p[i] = 1 if f_wb >= 0.5 else 0
return p
计算准确率:
p = predict(X_train, w, b)
print(f"训练准确率: {np.mean(p == y_train) * 100:.2f}%")
输出:
训练准确率: 92.00%
92% 的准确率——我们的模型表现不错!
3 - 正则化逻辑回归
现在,让我们处理一个更复杂的数据集,其中直线无法有效分隔数据。
3.1 新问题
假设你是一名工厂经理,通过两次测试来检测芯片。你希望根据测试成绩预测芯片是否通过质量检测(1 表示通过,0 表示未通过)。
3.2 数据洞察
加载数据:
X_train, y_train = load_data("data/ex2data2.txt")
查看数据:
print("X_train[:5]:\n", X_train[:5])
print("y_train[:5]:\n", y_train[:5])
输出:
X_train[:5]:
[[ 0.051267 0.69956 ]
[-0.092742 0.68494 ]
[-0.21371 0.69225 ]
[-0.375 0.50219 ]
[-0.51325 0.46564 ]]
y_train[:5]:
[1. 1. 1. 1. 1.]
可视化:
plot_data(X_train, y_train, pos_label="通过", neg_label="未通过")
plt.ylabel('芯片测试2')
plt.xlabel('芯片测试1')
plt.legend(loc="upper right")
plt.show()
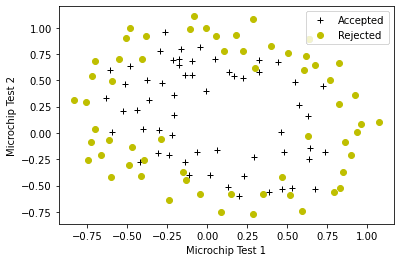
数据呈现非线性模式,表明我们需要一个更灵活的模型。
3.3 特征映射
为了捕捉复杂性,我们将特征映射到最高 6 次的多项式:
X_mapped = map_feature(X_train[:, 0], X_train[:, 1])
print("原始形状:", X_train.shape)
print("映射后形状:", X_mapped.shape)
输出:
原始形状: (118, 2)
映射后形状: (118, 27)
从 2 个特征扩展到 27 个特征——这将有助于拟合数据,但也可能导致过拟合。
3.4 正则化成本函数
添加惩罚项以防止过拟合:
实现它:
def compute_cost_reg(X, y, w, b, lambda_=1):
m = X.shape[0]
cost = compute_cost(X, y, w, b)
reg_cost = (lambda_ / (2 * m)) * np.sum(w ** 2)
return cost + reg_cost
3.5 正则化梯度
调整梯度:
编码:
def compute_gradient_reg(X, y, w, b, lambda_=1):
dj_dw, dj_db = compute_gradient(X, y, w, b)
dj_dw += (lambda_ / X.shape[0]) * w
return dj_dw, dj_db
3.6 带正则化的训练
训练模型:
np.random.seed(1)
initial_w = np.random.rand(X_mapped.shape[1]) - 0.5
initial_b = 1.0
lambda_ = 0.01
w, b, J_history = gradient_descent(X_mapped, y_train, initial_w, initial_b,
compute_cost_reg, compute_gradient_reg, 0.01, 10000)
输出:
迭代 0: 成本 0.72
迭代 1000: 成本 0.59
...
迭代 9999: 成本 0.45
成本稳步下降。
3.7 复杂边界的可视化
绘制决策边界:
plot_decision_boundary(w, b, X_mapped, y_train)
plt.ylabel('芯片测试2')
plt.xlabel('芯片测试1')
plt.legend(loc="upper right")
plt.show()
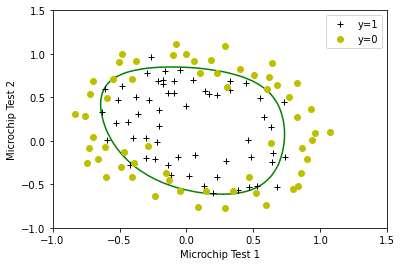
弯曲的边界很好地拟合了数据!
3.8 评估正则化模型
检查准确率:
p = predict(X_mapped, w, b)
print(f"训练准确率: {np.mean(p == y_train) * 100:.2f}%")
输出:
训练准确率: 82.20%
对于一个非线性问题,82% 的准确率相当不错!
4 - 交互式可视化探索
为了更直观地理解逻辑回归的工作原理,这里准备了三个交互式可视化工具:
4.1 Sigmoid函数可视化
Sigmoid函数是逻辑回归的核心,它将任意实数映射到(0,1)区间:
观察要点:
- 📈 S形曲线:输出值在0到1之间
- 🎯 中心点:z=0时,sigmoid(0)=0.5
- 📊 饱和区:|z|很大时,函数趋于平坦
4.2 决策边界交互式调整
这个可视化展示了如何通过调整参数来改变决策边界:
使用提示:
- 拖动滑块调整权重参数
- 观察决策边界如何变化
- 查看分类准确率的实时更新
4.3 正则化效果对比
这个可视化展示了不同正则化强度对模型的影响:
对比观察:
- 🔴 无正则化:可能过拟合
- 🟢 适度正则化:平衡拟合
- 🔵 过度正则化:欠拟合
5 - 深入理解逻辑回归
5.1 为什么使用Sigmoid函数?
逻辑回归需要输出概率值(0到1之间),Sigmoid函数完美满足这个需求。
Sigmoid的数学性质
def sigmoid(z):
"""
Sigmoid函数:g(z) = 1 / (1 + e^(-z))
"""
return 1 / (1 + np.exp(-z))
# 重要性质
z_values = np.array([-10, -5, 0, 5, 10])
sigmoid_values = sigmoid(z_values)
print("z值:", z_values)
print("sigmoid(z):", sigmoid_values)
print("\n性质验证:")
print("sigmoid(0) =", sigmoid(0)) # 0.5
print("sigmoid(-z) + sigmoid(z) =", sigmoid(-5) + sigmoid(5)) # 1.0
输出:
z值: [-10 -5 0 5 10]
sigmoid(z): [0.0000454 0.0066929 0.5 0.9933071 0.9999546]
性质验证:
sigmoid(0) = 0.5
sigmoid(-z) + sigmoid(z) = 1.0
关键性质:
- 对称性:sigmoid(-z) = 1 - sigmoid(z)
- 单调性:z越大,sigmoid(z)越接近1
- 可导性:导数为 g'(z) = g(z)(1-g(z))
5.2 成本函数的直觉理解
为什么逻辑回归使用对数损失而不是均方误差?
对数损失的优势
def visualize_loss_functions():
"""
对比不同损失函数
"""
# 真实标签 y=1 的情况
predictions = np.linspace(0.01, 0.99, 100)
# 对数损失:-log(h)
log_loss = -np.log(predictions)
# 均方误差:(1-h)^2
mse_loss = (1 - predictions) ** 2
plt.figure(figsize=(12, 5))
# 子图1:y=1时的损失
plt.subplot(1, 2, 1)
plt.plot(predictions, log_loss, 'b-', label='对数损失', linewidth=2)
plt.plot(predictions, mse_loss, 'r--', label='均方误差', linewidth=2)
plt.xlabel('预测概率 h(x)')
plt.ylabel('损失值')
plt.title('当真实标签 y=1 时')
plt.legend()
plt.grid(True, alpha=0.3)
# 子图2:y=0时的损失
plt.subplot(1, 2, 2)
log_loss_0 = -np.log(1 - predictions)
mse_loss_0 = predictions ** 2
plt.plot(predictions, log_loss_0, 'b-', label='对数损失', linewidth=2)
plt.plot(predictions, mse_loss_0, 'r--', label='均方误差', linewidth=2)
plt.xlabel('预测概率 h(x)')
plt.ylabel('损失值')
plt.title('当真实标签 y=0 时')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
visualize_loss_functions()
对数损失的优势:
- ✅ 强惩罚:错误预测的惩罚更大
- ✅ 凸函数:保证全局最优解
- ✅ 梯度友好:导数形式简洁
5.3 梯度下降的收敛分析
学习率的影响
def compare_learning_rates(X, y, alphas=[0.001, 0.01, 0.1, 1.0]):
"""
对比不同学习率的收敛情况
"""
plt.figure(figsize=(12, 8))
for alpha in alphas:
w = np.zeros(X.shape[1])
b = 0
costs = []
for i in range(1000):
z = np.dot(X, w) + b
h = sigmoid(z)
# 计算成本
cost = compute_cost(X, y, w, b)
costs.append(cost)
# 梯度下降
dw = np.dot(X.T, (h - y)) / len(y)
db = np.sum(h - y) / len(y)
w = w - alpha * dw
b = b - alpha * db
plt.plot(costs, label=f'α={alpha}', linewidth=2)
plt.xlabel('迭代次数')
plt.ylabel('成本函数值')
plt.title('不同学习率的收敛对比')
plt.legend()
plt.grid(True, alpha=0.3)
plt.yscale('log') # 对数刻度更清晰
plt.show()
# 运行对比
compare_learning_rates(X_train, y_train)
观察结果:
- 🐌 α=0.001:收敛慢但稳定
- ✅ α=0.01:收敛速度适中
- ⚡ α=0.1:快速收敛
- ❌ α=1.0:可能震荡或发散
5.4 正则化的数学原理
正则化通过在成本函数中添加惩罚项来防止过拟合。
L2正则化(Ridge)
def regularized_cost(X, y, w, b, lambda_):
"""
带L2正则化的成本函数
J(w,b) = 原始成本 + (λ/2m) * Σw²
"""
m = len(y)
# 原始成本
z = np.dot(X, w) + b
h = sigmoid(z)
cost = -np.mean(y * np.log(h) + (1-y) * np.log(1-h))
# 正则化项(不包括偏置b)
reg_cost = (lambda_ / (2 * m)) * np.sum(w ** 2)
return cost + reg_cost
正则化强度的选择
def find_best_lambda(X_train, y_train, X_val, y_val):
"""
通过验证集选择最佳正则化参数
"""
lambdas = [0, 0.001, 0.01, 0.1, 1, 10, 100]
train_errors = []
val_errors = []
for lambda_ in lambdas:
# 训练模型
w, b = train_with_regularization(X_train, y_train, lambda_)
# 计算误差
train_error = compute_cost(X_train, y_train, w, b)
val_error = compute_cost(X_val, y_val, w, b)
train_errors.append(train_error)
val_errors.append(val_error)
# 可视化
plt.figure(figsize=(10, 6))
plt.plot(lambdas, train_errors, 'b-o', label='训练误差', linewidth=2)
plt.plot(lambdas, val_errors, 'r-o', label='验证误差', linewidth=2)
plt.xlabel('正则化参数 λ')
plt.ylabel('成本函数值')
plt.title('正则化参数选择')
plt.xscale('log')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
# 选择验证误差最小的λ
best_lambda = lambdas[np.argmin(val_errors)]
print(f"最佳正则化参数: λ = {best_lambda}")
return best_lambda
6 - 实战技巧与常见问题
6.1 特征工程技巧
特征缩放的重要性
def feature_scaling_comparison(X, y):
"""
对比特征缩放前后的收敛速度
"""
from sklearn.preprocessing import StandardScaler
# 未缩放的训练
w1, b1, costs1 = train_logistic_regression(X, y, alpha=0.01, iterations=1000)
# 缩放后的训练
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
w2, b2, costs2 = train_logistic_regression(X_scaled, y, alpha=0.01, iterations=1000)
# 对比收敛曲线
plt.figure(figsize=(10, 6))
plt.plot(costs1, label='未缩放', linewidth=2)
plt.plot(costs2, label='已缩放', linewidth=2)
plt.xlabel('迭代次数')
plt.ylabel('成本函数值')
plt.title('特征缩放对收敛速度的影响')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
特征缩放方法:
- 标准化(Z-score)
X_scaled = (X - X.mean(axis=0)) / X.std(axis=0)
- 归一化(Min-Max)
X_normalized = (X - X.min(axis=0)) / (X.max(axis=0) - X.min(axis=0))
多项式特征创建
def create_polynomial_features(X, degree=2):
"""
创建多项式特征
例如:[x1, x2] -> [x1, x2, x1², x1*x2, x2²]
"""
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=degree, include_bias=False)
X_poly = poly.fit_transform(X)
print(f"原始特征数: {X.shape[1]}")
print(f"多项式特征数: {X_poly.shape[1]}")
print(f"特征名称: {poly.get_feature_names_out()}")
return X_poly
6.2 模型评估指标
准确率不是唯一的评估指标,特别是在类别不平衡的情况下。
混淆矩阵
def plot_confusion_matrix(y_true, y_pred):
"""
绘制混淆矩阵
"""
from sklearn.metrics import confusion_matrix
import seaborn as sns
cm = confusion_matrix(y_true, y_pred)
plt.figure(figsize=(8, 6))
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',
xticklabels=['预测负类', '预测正类'],
yticklabels=['实际负类', '实际正类'])
plt.title('混淆矩阵')
plt.ylabel('实际标签')
plt.xlabel('预测标签')
plt.show()
# 计算指标
tn, fp, fn, tp = cm.ravel()
accuracy = (tp + tn) / (tp + tn + fp + fn)
precision = tp / (tp + fp)
recall = tp / (tp + fn)
f1_score = 2 * (precision * recall) / (precision + recall)
print(f"准确率 (Accuracy): {accuracy:.4f}")
print(f"精确率 (Precision): {precision:.4f}")
print(f"召回率 (Recall): {recall:.4f}")
print(f"F1分数: {f1_score:.4f}")
ROC曲线和AUC
def plot_roc_curve(X, y, w, b):
"""
绘制ROC曲线
"""
from sklearn.metrics import roc_curve, auc
# 获取预测概率
z = np.dot(X, w) + b
y_prob = sigmoid(z)
# 计算ROC曲线
fpr, tpr, thresholds = roc_curve(y, y_prob)
roc_auc = auc(fpr, tpr)
# 绘制
plt.figure(figsize=(8, 6))
plt.plot(fpr, tpr, 'b-', linewidth=2,
label=f'ROC曲线 (AUC = {roc_auc:.3f})')
plt.plot([0, 1], [0, 1], 'r--', linewidth=2, label='随机猜测')
plt.xlabel('假正率 (FPR)')
plt.ylabel('真正率 (TPR)')
plt.title('ROC曲线')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
return roc_auc
6.3 类别不平衡处理
当正负样本数量差异很大时,需要特殊处理。
方法1:调整类别权重
def weighted_logistic_regression(X, y, pos_weight=1.0):
"""
带类别权重的逻辑回归
pos_weight: 正类样本的权重倍数
"""
def weighted_cost(w, b):
z = np.dot(X, w) + b
h = sigmoid(z)
# 为正类样本增加权重
weights = np.where(y == 1, pos_weight, 1.0)
cost = -np.mean(weights * (y * np.log(h) + (1-y) * np.log(1-h)))
return cost
# 训练过程类似,但使用加权成本
# ...
方法2:重采样
def balance_dataset(X, y, method='oversample'):
"""
平衡数据集
method: 'oversample' 或 'undersample'
"""
from imblearn.over_sampling import SMOTE
from imblearn.under_sampling import RandomUnderSampler
if method == 'oversample':
# SMOTE过采样
smote = SMOTE(random_state=42)
X_balanced, y_balanced = smote.fit_resample(X, y)
else:
# 欠采样
rus = RandomUnderSampler(random_state=42)
X_balanced, y_balanced = rus.fit_resample(X, y)
print(f"原始数据: 正类={np.sum(y==1)}, 负类={np.sum(y==0)}")
print(f"平衡后: 正类={np.sum(y_balanced==1)}, 负类={np.sum(y_balanced==0)}")
return X_balanced, y_balanced
6.4 调试检查清单
遇到问题时,按以下顺序检查:
数据检查
- 标签是否为0/1?
- 是否有缺失值?
- 特征范围是否合理?
Sigmoid函数检查
- 是否处理了数值溢出?
- 输出是否在(0,1)范围内?
成本函数检查
- 初始成本是否合理(约0.693)?
- 成本是否单调递减?
- 是否出现NaN或Inf?
梯度检查
- 使用数值梯度验证
- 梯度量级是否合理?
学习率调优
- 从小值开始(0.001)
- 观察成本曲线
- 避免震荡或发散
6.5 性能优化技巧
向量化实现
# ❌ 慢速循环版本
def predict_slow(X, w, b):
predictions = []
for i in range(len(X)):
z = np.dot(X[i], w) + b
predictions.append(sigmoid(z))
return np.array(predictions)
# ✅ 快速向量化版本
def predict_fast(X, w, b):
z = np.dot(X, w) + b
return sigmoid(z)
# 性能对比
import time
start = time.time()
pred_slow = predict_slow(X_train, w, b)
time_slow = time.time() - start
start = time.time()
pred_fast = predict_fast(X_train, w, b)
time_fast = time.time() - start
print(f"循环版本: {time_slow*1000:.2f} ms")
print(f"向量化版本: {time_fast*1000:.2f} ms")
print(f"加速比: {time_slow/time_fast:.1f}x")
7 - 扩展学习方向
掌握了逻辑回归后,你可以继续探索:
7.1 多分类问题
One-vs-Rest策略:
def one_vs_rest_classifier(X, y, num_classes):
"""
一对多分类器
"""
models = []
for c in range(num_classes):
# 将类别c视为正类,其他为负类
y_binary = (y == c).astype(int)
# 训练二分类器
w, b = train_logistic_regression(X, y_binary)
models.append((w, b))
return models
def predict_multiclass(X, models):
"""
多分类预测
"""
probabilities = []
for w, b in models:
z = np.dot(X, w) + b
prob = sigmoid(z)
probabilities.append(prob)
# 选择概率最大的类别
probabilities = np.array(probabilities).T
predictions = np.argmax(probabilities, axis=1)
return predictions
7.2 Softmax回归
多分类的另一种方法:
def softmax(z):
"""
Softmax函数:将logits转换为概率分布
"""
exp_z = np.exp(z - np.max(z, axis=1, keepdims=True)) # 数值稳定
return exp_z / np.sum(exp_z, axis=1, keepdims=True)
7.3 高级优化算法
除了梯度下降,还有更高效的优化器:
- Adam:自适应学习率
- RMSprop:适合非平稳目标
- L-BFGS:二阶优化方法
7.4 深度学习的桥梁
逻辑回归是神经网络的基础:
逻辑回归 → 单层神经网络 → 多层神经网络 → 深度学习
总结
恭喜你完成了这场逻辑回归的实践之旅!你已经学会了:
- 使用真实数据预测二分类结果。
- 编码核心函数并优化它们。
- 可视化结果以理解模型。
- 使用正则化处理复杂模式。
你可以尝试调整参数,如 alpha 或 lambda_,看看模型如何变化。继续探索,快乐学习!
本篇文章的部分内容和思想参考了 吴恩达 (Andrew Ng) 在 Coursera 机器学习课程 中的讲解,感谢他对机器学习领域的卓越贡献。